Diving deep into the process of image-based generative AI. A place where complex mathematics borders on magic.
For a thirteen-minute deep dive into this process, based on the ideas expressed in this post, click on the audio player below.
When I use Midjourney V7, the AI image generator, and provide a source image as the first part of the prompt, the AI generates a sequence of images based on this image. How the Midjourney AI uses that image to generate its subsequent sequence of images often feels like magic. But it’s not. It’s just very, very complex math.
First, the source image is used by the AI as the input to a process known as “conditioning.” With this initial step, the provided photo is encoded into a latent representation that serves as part of the “context” for the generative process. MidJourney then blends the semantic features of the image with the concepts of the subsequent prompt.
That’s all well and good, but let’s go deeper down the rabbit hole. A place where mathematics and magic fuse.
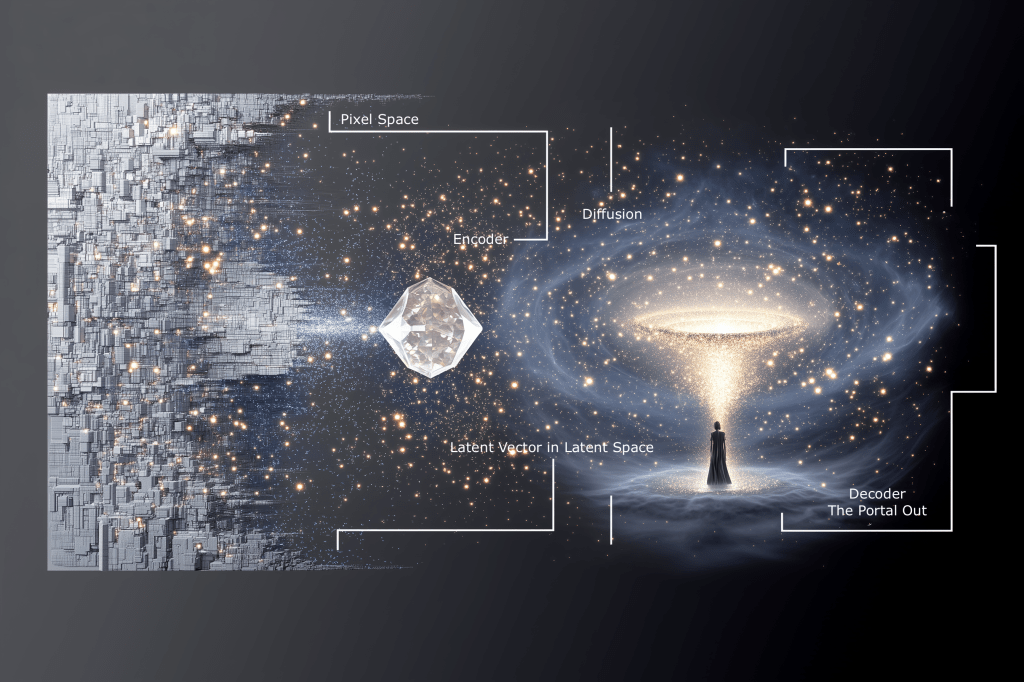
Behind the scenes, an image passed into MidJourney goes through several steps:
- Encoding
- The source image is transformed into a latent vector (a dense numerical representation).
- This is usually done with a pretrained vision encoder (often CLIP, or something similar).
- That embedding captures high-level features: shapes, colours, composition, textures, object categories, and even style.
- Conditioning the Diffusion Process
- The encoded image is fed into the diffusion model as a “prior state.”
- The diffusion model uses this as a strong reference point to guide how noise is denoised into the output image.
- The text prompt is encoded separately (also into a latent space), and both signals interact.
- The weighting between image and text can often be tuned (MidJourney doesn’t expose this in raw numbers like Stable Diffusion does, but it’s happening under the hood).
- Generating Variations
- Each of the four images you see in the initial grid is a different sampling path through that noisy latent space, but all of them are influenced by the encoded source image.
- That’s why you see continuity in subject, shape, or style—but with variation in pose, background, or detail.
- Subsequent Upscales or Variations
- When you “V” (variation) or “U” (upscale), the system reuses that latent conditioning in a refined or re-sampled form, keeping some fidelity to the original while exploring alternatives.
Since your still reading (a) thanks! and (b) I’ll take this as an invitation to travel even deeper into this techno-magical rabbit hole that is generative AI.
What are “latent vectors” and “latent spaces,” and are they what, in the world of generative AI, are referred to as “collections of tensors”?
1. Tensor Basics
- A tensor is just a generalization of scalars, vectors, and matrices:
- Scalar = 0-dimensional tensor (a single number).
- Vector = 1D tensor (a list of numbers).
- Matrix = 2D tensor (rows and columns).
- Higher-dimensional tensors (3D, 4D, etc.) are used for images, videos, batches of data, etc.
In AI, tensors are the fundamental data structure. Frameworks like PyTorch or TensorFlow are basically tensor libraries with auto-differentiation.
2. Latent Vector
- A latent vector is a compressed numerical representation of something complex (like an image, a sound clip, or a sentence).
- Example: You give the AI a 1024×1024 image (over a million pixel values). A vision encoder compresses it into, say, a 768-dimensional vector. That vector is “latent” because:
- It’s hidden, not human-interpretable.
- It encodes high-level features (“dogness,” “fur texture,” “looking left”) instead of raw pixel data.
Mathematically, that latent vector is still just a tensor — usually 1D, but sometimes with multiple dimensions (channels × width × height).
3. Latent Space
- If you imagine all possible latent vectors as points, you get a latent space.
- Latent space is like a compressed map of the possible configurations the model has learned.
- In a text-to-image model, nearby points in latent space correspond to visually similar images.
- Moving smoothly through latent space (interpolation) can morph one image into another.
It’s “space” in the mathematical sense — a multidimensional manifold where geometry (distances, directions) corresponds to semantic meaning.
4. How They Connect in Generative AI
- The diffusion model doesn’t work directly in pixel space (that would be too big and messy).
- Instead, it works in latent space.
- The model starts with random noise in latent space (a tensor of noise).
- Each diffusion step denoises it, guided by your text and/or image prompt.
- At the end, the latent tensor is decoded back into pixels by a decoder network.
So when we say “latent vector”, we’re talking about a single tensor point in that latent space.
When we say “latent space”, we’re talking about the entire tensor space the model operates in.
5. The TLDR Version
- Tensors are the underlying structure for both latent vectors and latent spaces.
- A latent vector is a tensor (often 1D, sometimes 3D).
- A latent space is the collection of all such tensors, treated as a continuous high-dimensional space.
- What makes them “latent” is not the math itself, but the fact that they represent compressed, hidden features learned by the model.
👉 So you could say:
- Tensor space = the mathematical foundation (raw multidimensional numbers).
- Latent space = a specific tensor space the model learned to use as a compressed, meaningful representation of data.
Now you know.

Leave a comment